Recently, the YodaQA team is collaborating with Falk Pollok from RWTH Aachen who is interested in using Question Answering in education to help people digest what they have learned better and to generally assist with studying. To this end, he has created PalmQA – a QA application that multiplexes between many question answering backends, ensembling them together to a more accurate system.
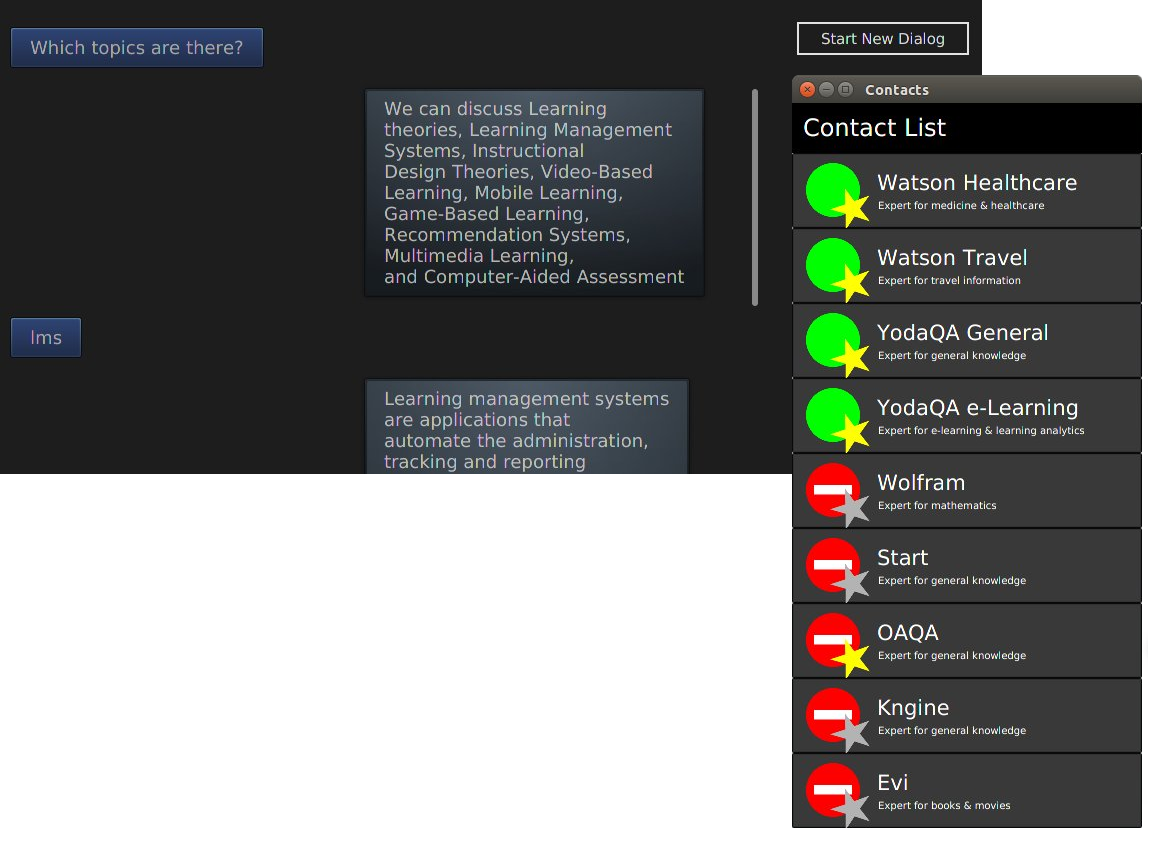
Falk has built backends for IBM Watson’s DeepQA among others (Google, Evi, Kngine and MIT’s Start), but in the end, the combination of YodaQA and Wolfram Alpha is “a match made in heaven,” as Falk said in an email a short while ago.
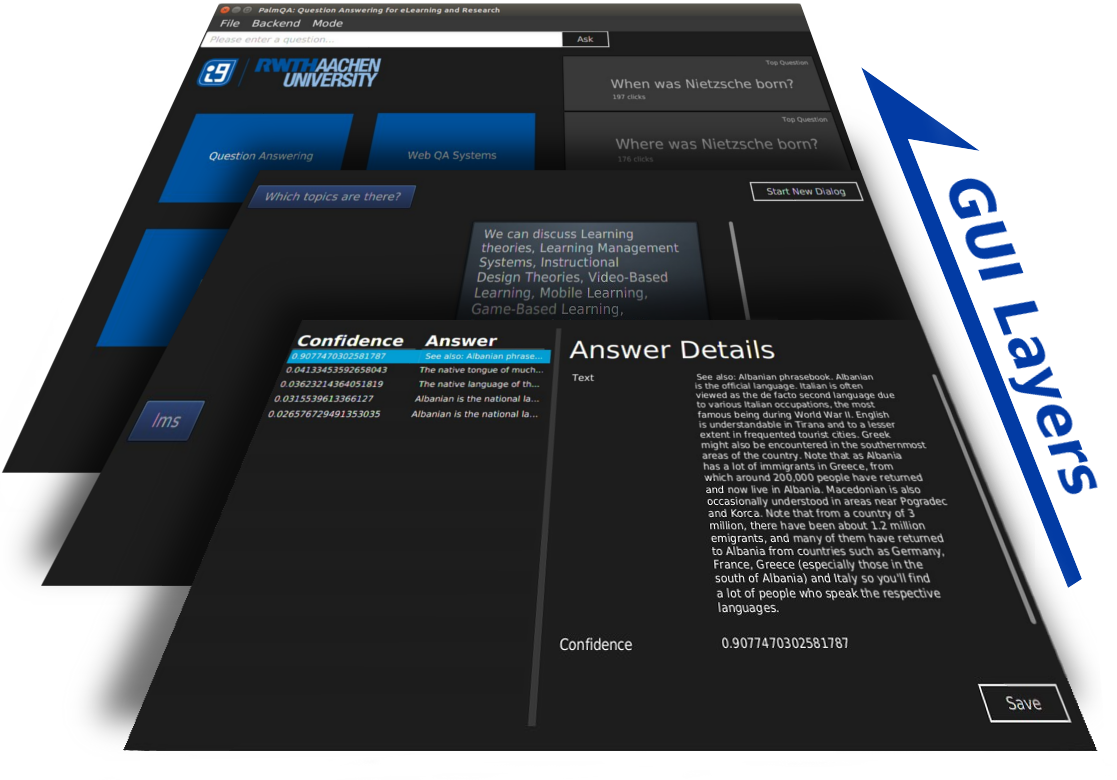

As a finishing touch to his work (being submitted as a diploma thesis), Falk made a Grand Challenge – letting an independent third party make a list of 30 factoid questions of varying difficulty, and pitching the PalmQA against a wide variety of humans. Perhaps not quite as dramatic or grandiose as IBM Watson’s Jeopardy participation, but still a nice showcase of where we are now.
Well, PalmQA did great! 26 people competed, and typically could get about 15 out of the 30 right. The best human answered 24 questions correctly. But no matter – PalmQA managed to answer 25 out of 30 questions right!
So, in this challenge, Falk’s ensemble-enhanced YodaQA beats the best human!
As mentioned above, PalmQA offers integration of YodaQA with Wolfram Alpha, Google QA, MIT’s Start, Amazon’s Evi and Kngine. We hope to merge this ensembling system into the YodaQA project in the future!
I also entered just plain YodaQA into the Grand Challenge, in the configuration that’s running at live.ailao.eu right now. It got 18 questions right, still better than an average human! If we also included purely “computational” questions (algebra, unit conversions) that YodaQA just isn’t designed to answer (it’s still essentially a search engine), that’d make 24 questions out of 30. Pretty good!
See the Grand Challenge Github issue for more info. We should get the complete details of the challenge, comparisons to other public QA engines (like Google) etc. in Falk’s upcoming thesis.
This is how the plain YodaQA fared:
| Question Text |
|
correct |
found |
| What is the capital of Zimbabwe? |
✓ |
Harare |
Harare |
| Who invented the Otto engine? |
✓ |
Nikolaus Otto |
Nikolaus Otto |
| When was Pablo Picasso born? |
✓ |
1881 |
1881 |
| What is 7*158 + 72 – 72 + 9? |
✗ |
1115 |
78.182.71.65 78 |
| Who wrote the novel The Light Fantastic? |
✓ |
Terry Pratchett |
Terry Pratchett |
| In which city was Woody Allen born? |
✓ |
New York |
New York |
| Who is the current prime minister of Italy? |
✓ |
Matteo Renzi |
Matteo Renzi |
| What is the equatorial radius of Earth’s moon? |
✗ |
1738 |
the Moon and Su |
| When did the Soviet Union dissolve? |
✓ |
1991 |
1991 |
| What is the core body temperature of a human? |
✗ |
37 |
Bio 42 and cour |
| Who is the current Dalai Lama? |
✓ |
Tenzin Gyatso |
Tenzin Gyatso |
| What is 2^23? |
✗ |
8388608 |
the Gregorian c |
| Who is the creator of Star Trek? |
✓ |
Gene Roddenberr |
Gene Roddenberr |
| In which city is the Eiffel Tower? |
✓ |
Paris |
Paris |
| 12 metric tonnes in kilograms? |
✗ |
12 *000 |
SI |
| Where is the mouth of the river Rhine? |
✓ |
the Netherlands |
the Netherlands |
| Where is Buckingham Palace located? |
✓ |
London |
London |
| Who directed the movie The Green Mile? |
✓ |
Frank Darabont |
Frank Darabont |
| When did Franklin D. Roosevelt die? |
✓ |
1945 |
1945 |
| Who was the first man in space? |
✓ |
Yuri Gagarin |
Yuri Gagarin |
| Where was the Peace of Westphalia signed? |
✗ |
Osnabrück |
France |
| Who was the first woman to be awarded a Nobel Priz |
✗ |
Marie Curie |
Elinor Ostrom |
| 12.1147 inches to yards? |
✗ |
0.3365194444 |
CUX 570 17 577 |
| What is the atomic number of potassium? |
✓ |
19 |
19 |
| Where is the Tiananmen Square? |
✓ |
China |
China |
| What is the binomial name of horseradish? |
✓ |
Armoracia Rusti |
Armoracia Rusti |
| How long did Albert Einstein live? |
✗ |
76 |
Germany |
| Who earned the most Academy Awards? |
. |
Walt Disney |
Jimmy Stewart |
| How many lines does the London Underground have? |
✗ |
11 |
Soho Revue Bar |
| When is the next planned German Federal Convention |
✗ |
|
1850 |




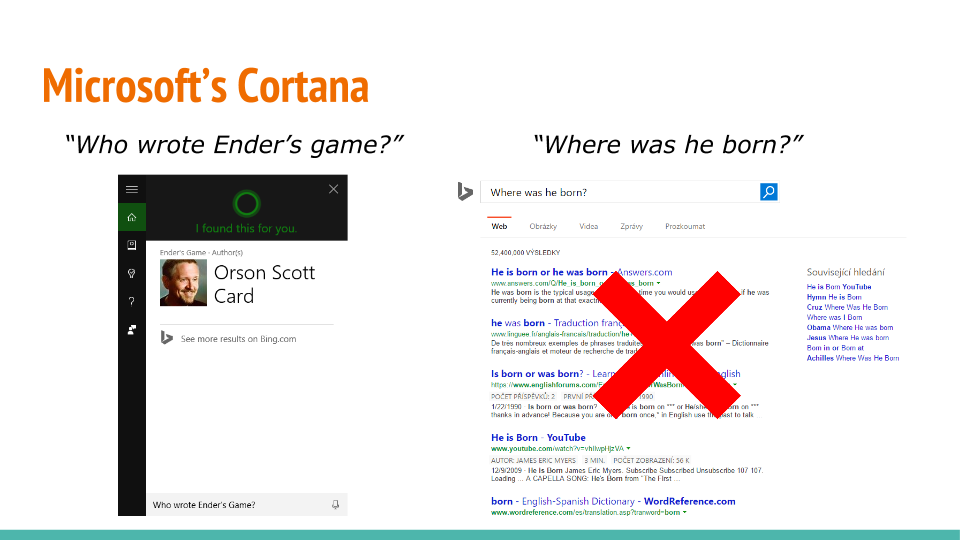


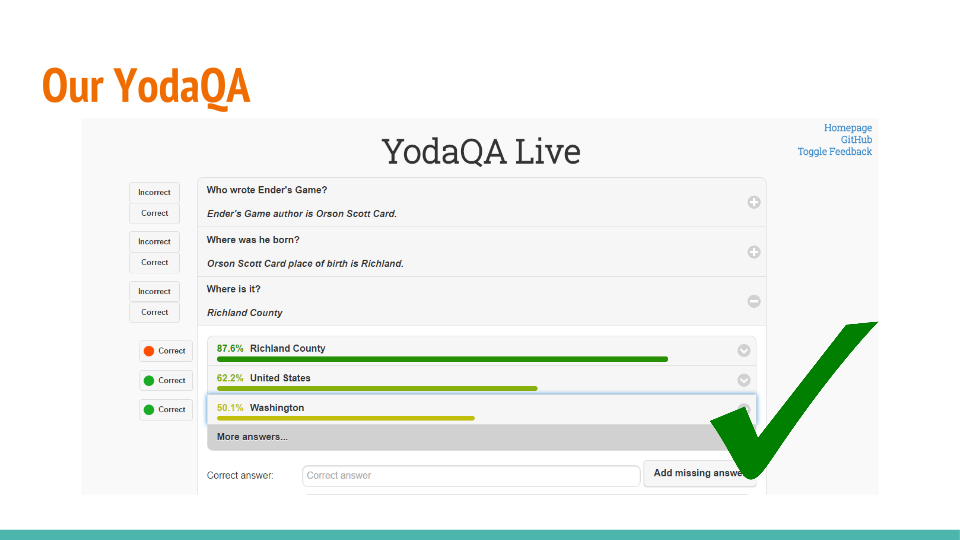


Recent Comments